The Encodian Flowr connector for Microsoft Power Automate provides the PDF – Apply OCR (Standard) (previously OCR a PDF Document) action, which will perform OCR on the supplied PDF document. Optionally, the action can also be configured to perform image clean-up operations such as auto-rotation, deskew, despeckle, etc.
Applying a text layer to PDF documents is important, as it ensures that search engines can index PDF document content and thus be found through search, it can also ensure data loss prevention rules can act on actual document content, and much more! However, OCR is computationally expensive, and therefore, it is sensible to only perform OCR when a document does not contain a text layer.
Consider the following Power Automate Flow, which is triggered every time a PDF document is added to a SharePoint library.
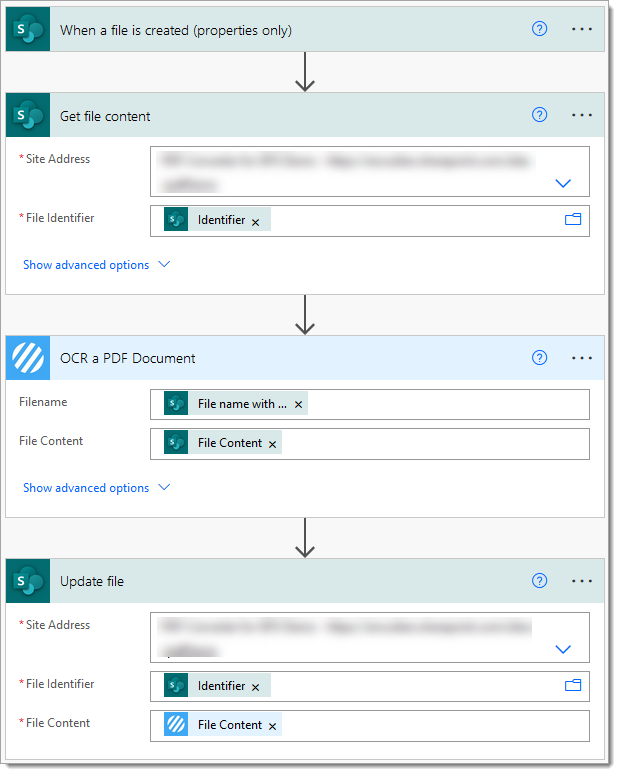
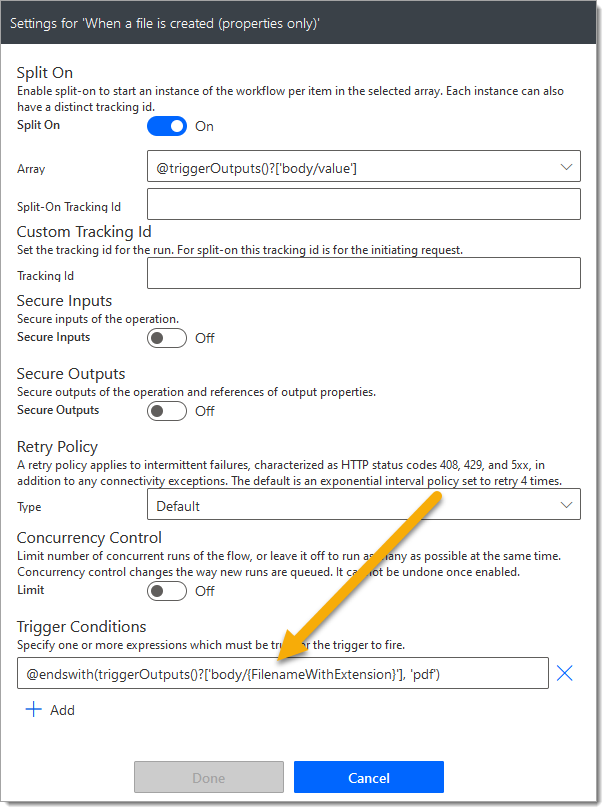
Note: The following trigger condition has been added to the trigger action to ensure the flow only fires for newly added PDF documents:
@endswith(triggerOutputs()?[‘body/{FilenameWithExtension}’], ‘pdf’)
Check the following video, which demonstrates how to create Power Automate trigger conditions the easy way!: Create Power Automate Trigger Conditions Simplified
Now back to OCR!
Currently, every single PDF document added to the SharePoint library will be OCR’d. Regardless of whether it has been OCR’d previously! To optimise the flow, we can add the PDF – Extract Metadata (previously Get PDF Document Information) action to check for the presence of a text layer within the document and then only perform OCR if it is required.
The PDF – Extract Metadata (previously Get PDF Document Information) action returns a ‘Has Text Layer‘ boolean value (True or False) which can be evaluated, consider this updated flow which now only OCR’s PDF documents which do not contain a text layer.
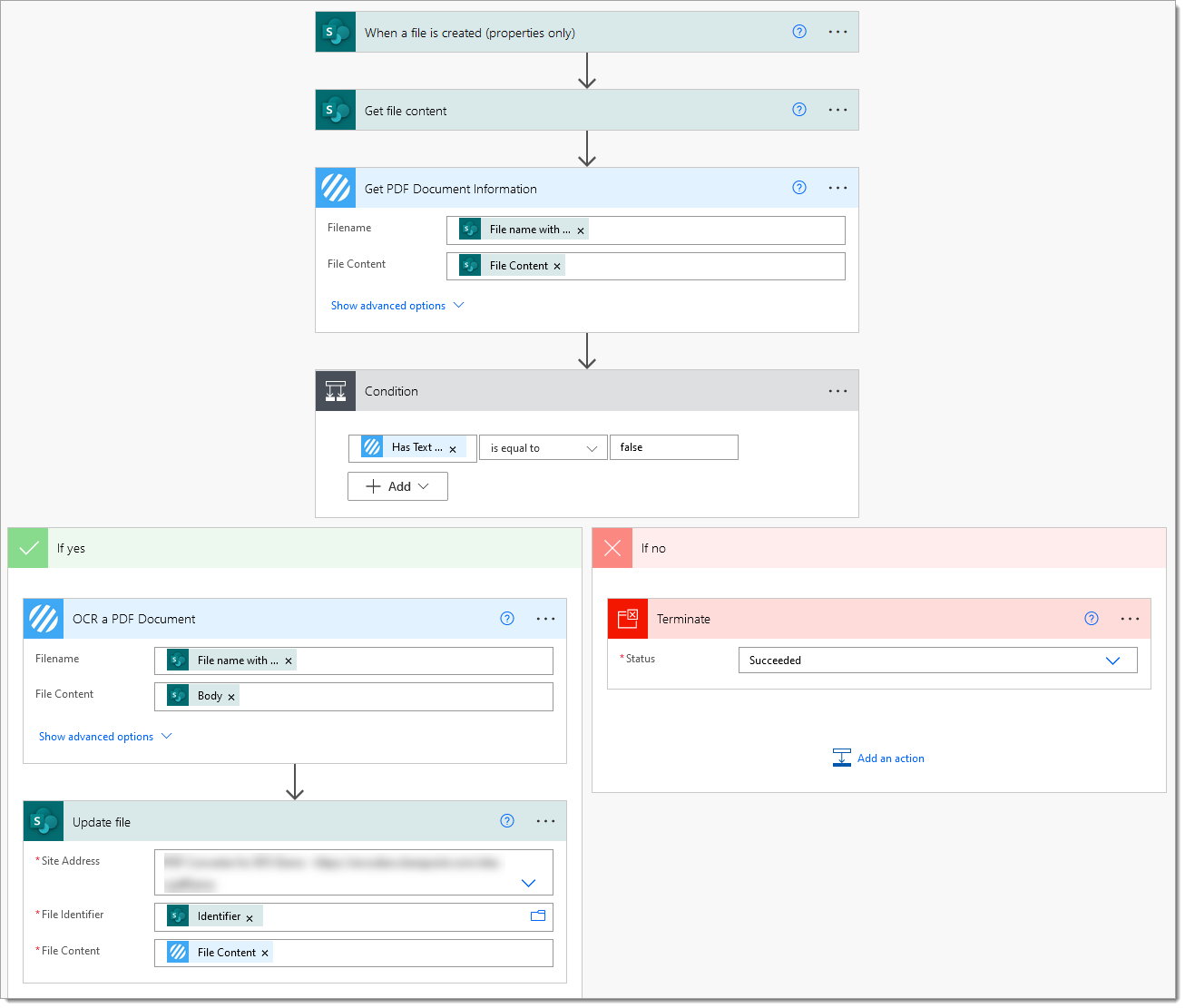
This updated flow will now only OCR PDF documents which do not contain a text layer!
Hopefully, this post outlines how you can use both the PDF – Apply OCR (Standard) (previously OCR a PDF Document) action and PDF – Extract Metadata (previously Get PDF Document Information) to perform conditional OCR. Please share your feedback and comments – all are welcome!
UPDATE: We’re excited to announce some significant updates to Flowr for Power Automate! As of October 2024, we’ve improved by updating action names and splitting Flowr’s central Power Automate connector into nine specialized connectors. These changes will make your workflow faster, smoother, and more efficient. The new action names are more precise and intuitive, saving you time, while the focused connectors enhance performance and flexibility. This update also helps future-proof the platform for even more powerful features. Check out our updated action names blog.
Managing Director

